FabFilter(肥波)插件1
FabFilter是荷兰一家广受赞誉的音频处理软件厂商,其生产的产品因其简单直观的用户界面、高质量音频处理和灵活的控制而备受推崇。
- FabFilter
Pro-Q 4:均衡器,具有完美的模拟建模、动态均衡器、线性相位处理和出色的界面,具有无与伦比的易用性。这款强大的均衡器插件能精细调整音频频率响应。 - FabFilter
Pro-DS:专业的消齿音(De-Esser)插件,主要用于消除人声录音中的高频嘶声(如“s”“sh”等齿音),同时也可用于其他高频动态控制。
Pro-Q 4
Fabfilter Pro-Q 4:音频行业标准的均衡器插件。集成了动态处理、频谱修复、模拟饱和及多实例管理。
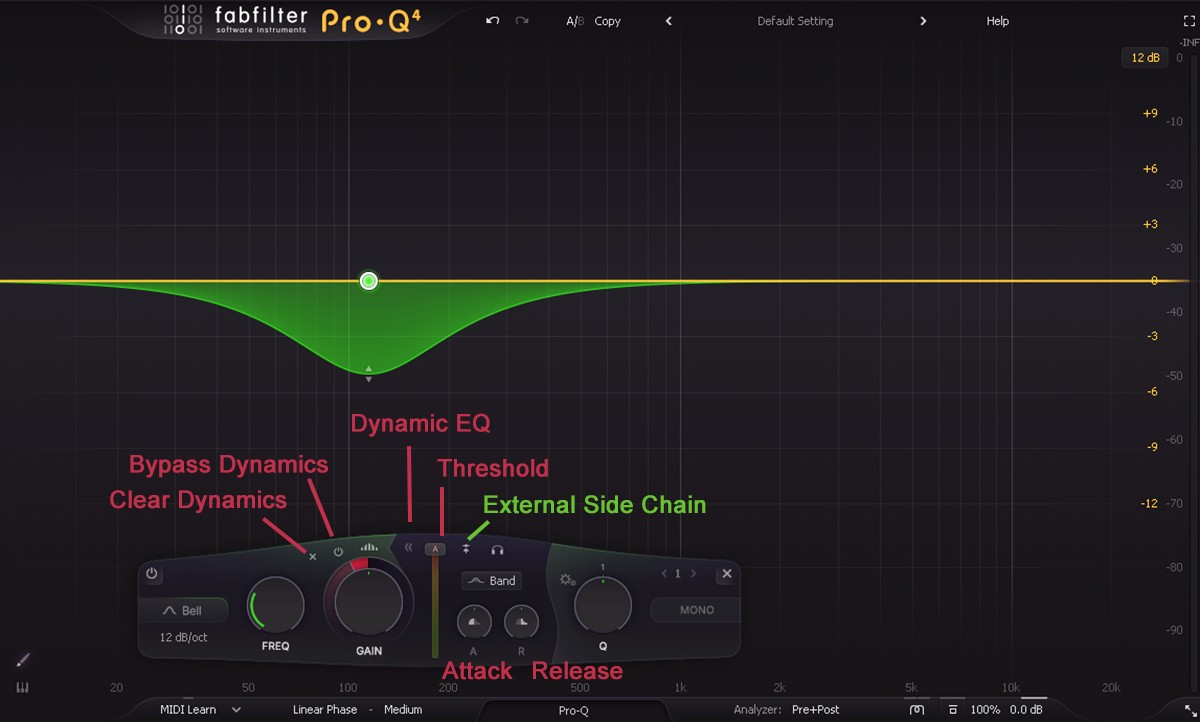
当频段被设为动态后,会显示额外的控制面板。点击动态范围环上的展开按钮(expand)可查看详细参数:
- External Side Chain:外部侧链。切换触发信号源。
- 默认:使用插件输入的信号(Input)。
- 开启后:使用外部侧链输入的信号作为触发源。这允许你用一条轨道的信号(如底鼓)去控制另一条轨道(如贝斯)的 EQ 变化。
- 注意:即使使用外部侧链,触发信号依然会受到上述"Band"或"Free"滤波设置的限制。
- Audition:试听按钮。按住此按钮可以单独听到用于触发的侧链信号,帮助你不凭猜测地设置触发频率。
- Clear Dynamics:将动态范围重置为 0 dB,完全移除动态属性,变回普通静态频段。
- Bypass Dynamics:暂时关闭动态行为,频段变回静态 EQ,但保留动态参数设置。
动态 EQ
- Triggering:触发源设置。
- Band:频段触发。默认。动态处理仅由该频段频率范围内的信号触发。这是最常用的模式,具有“手术刀”般的精准度。
- Free:自由触发。选择此项后,会出现额外的低切(Low-cut)和高切(High-cut)滤波器控件。你可以自定义触发信号的频率范围,使其不同于实际处理的频段。
- Threshold:阈值。设定触发动态处理的电平阈值。
- 自动模式(Auto):默认情况下,滑块位于顶部(显示"A"),阈值会根据带限触发信号的电平自动调整。
- 手动模式:点击展开面板后,可手动拖动滑块设定固定阈值。滑块上会显示触发信号的电平,辅助你找到合适的触发点。
- 软拐点(Soft Knee):算法内部使用软拐点,意味着处理会在略低于设定阈值时就开始平滑介入。
- Dynamic Range:动态范围。设定动态处理的强度,范围为-30 dB 到+30 dB。
- 负值:表示压缩(Compression)。当信号超过阈值时,增益会降低。
- 正值:表示扩展(Expansion)。当信号超过阈值时,增益会增加。
- 视觉:环内黄色的条形指示器显示当前的实时增益变化量,红色部分指示设定的动态范围上限。
- Attack & Release:启动与释放。控制动态变化的速度。
- 自动模式:中心位置(50%),代表自动模式,此时 Attack 和 Release 由插件根据音频内容自动优化。
- 手动调整:向左(低数值)调快,向右(高数值)调慢。这允许你对瞬态(如鼓的打击感)或长尾音进行更精确的控制。
Attack、Release、Knee,并不是固定的数值,而是取决于以下三个因素:
- 被处理的音频素材:插件会分析当前的音频内容。
- 均衡器频段所在的频率范围:不同频率会有不同的响应特性。
- 当前的动态范围设置:设定的压缩或扩展强度也会影响响应时间。
结果:这种设计能产生非常自然、平滑的压缩和扩展效果,适用于广泛的动态均衡应用场景,无需用户手动去“死磕”毫秒数。
- 默认设置:50%(全自动模式)
- 自动模式:当你把旋钮保持在正中间的 50%位置时,激活 Pro-Q 4 的智能程序依赖模式。
- 如何工作:此时,插件会根据你当前处理的频率(低频通常慢,高频通常快)、音频素材(瞬态强的声音反应快)以及动态范围(压缩得越狠,反应越平滑)自动计算最佳时间。
- 适用场景:90%的情况。对于大多数人声旁白、音乐混音,这个默认设置能提供最自然、最不易察觉的处理效果,完全不需要你手动干预。
- 手动微调:当你觉得智能模式不够完美,需要更极端的控制时,你需要打破 50%的平衡。
- 向左旋转(0%- 49%):追求“更快、更硬”
- 逻辑:你告诉算法:“我要比自动模式更快的反应速度。”
- 听感变化:旋钮越接近 0%,Attack/Release 时间越短。压缩器会像一堵墙一样瞬间抓住声音。
- Attack 调快:当你需要消除极快的瞬态噪音(如极尖锐的齿音、爆破音),且自动模式反应不过来时。
- Release 调快:当你需要极高频的“抽吸”效果(特殊音效),或者处理极短促的打击乐时。如果你觉得声音的尾音还在“乱窜”或者压缩感不够紧实,尝试将 Release 向左(快)微调,比如到 40%。
- 向右旋转(51%- 100%):追求“更慢、更柔”
- 逻辑:你告诉算法:“我要比自动模式更慢的恢复速度。”
- 听感变化:旋钮越接近 100%,时间越长。压缩器会变得“迟钝”,慢慢抓住声音,慢慢松开。
- Attack 调慢:当你想保留低频的冲击力(Punch),不想让压缩器把低音的“头”削掉时。如果你觉得声音被压得有点“闷”或失去了弹性,尝试将 Attack 向右(慢)微调,比如到 60%。
- Release 调慢:当你想让人声或贝斯的尾音更平滑、更连贯,避免音量忽大忽小(呼吸感)时。
- 向左旋转(0%- 49%):追求“更快、更硬”
不要把它当成“时间设置”,要把它当成“性格设置”。
- 人声旁白:直接保持 50%(Auto)。这是 Pro-Q 4 最强大的地方,它算得比你准。
- 低频乐器(贝斯/底鼓):尝试将 Attack 调至 60%-70%(稍慢),保留低频的“打击感”。
- 刺耳的高频(镲片/齿音):尝试将 Attack 调至 30%-40%(稍快),更精准地抓住刺耳的瞬间。
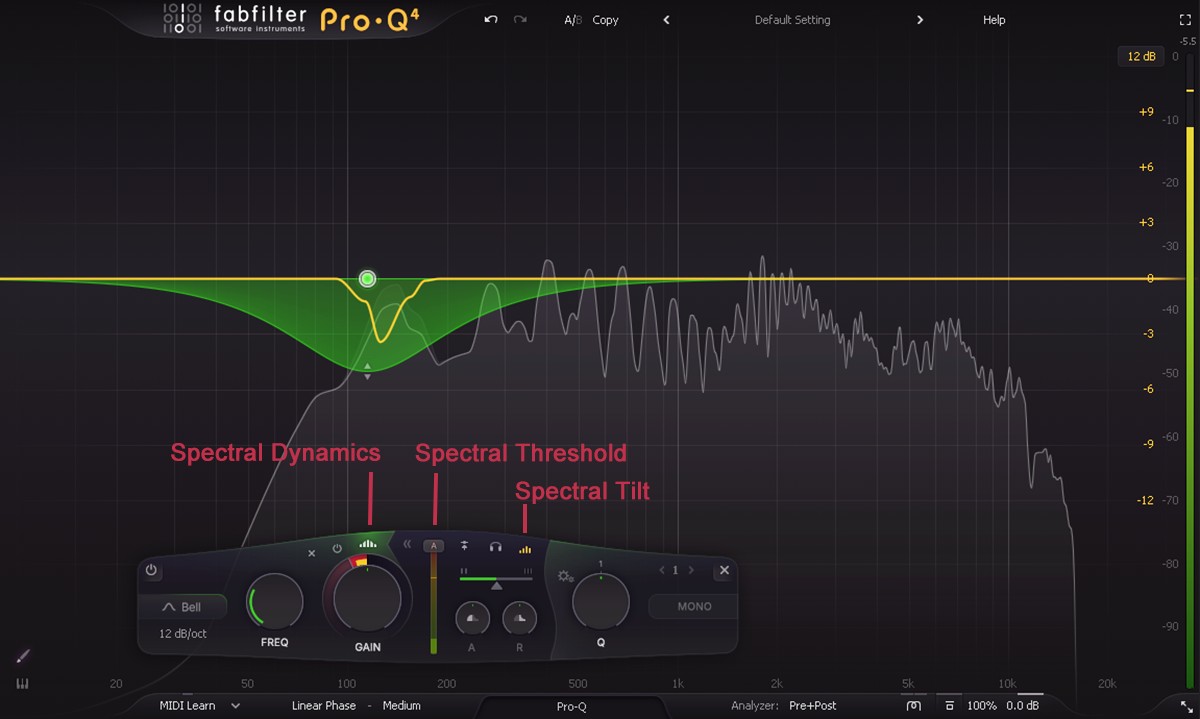
频谱动态(Spectral Dynamics)
- Threshold:在 Spectral Dynamics 模式下,阈值并不决定“信号电平达到多少才开始工作”,而是作为一个灵敏度参考点,用于配合“频谱密度(Spectral Density)”来决定“什么样的频谱差异”会触发处理。
- 自动状态:默认值 Auto。阈值是自动设定的(显示为'A')。Pro-Q 4 会根据输入信号的频谱特性自动计算最佳的触发灵敏度,通常不需要手动干预。
- 手动模式:设定一个基准线。动态处理会根据当前频谱与这个基准线的差异来进行。
- 触发条件:结合 Spectral Density(频谱密度)参数,如果某个特定频率的能量“凸起”超过了由阈值设定的灵敏度范围,该频率就会被识别为需要处理的目标。
- 调高阈值(数值变大):会降低触发的灵敏度。这意味着只有那些非常明显、能量极高的“尖峰”频率才会被处理。适合处理非常强烈的、偶发的刺耳频率。
- 调低阈值(数值变小):会增加触发的灵敏度。这会让处理范围变宽,插件会去修正更多微小的频谱偏差。适合处理持续存在但幅度不大的共振峰。
- Spectral Density:频谱密度,控制处理的“选择性”。
- 低值:触发的频率范围较宽。
- 高值:触发的范围非常窄且精确,只针对特定的频率峰。
- 低密度+高阈值:触发范围宽但条件苛刻,适合处理大范围的、强烈的频率冲突。
- 高密度+低阈值:触发范围窄且非常灵敏,适合精准“切除”人声中细小的齿音或尖锐共振。
- Spectral Tilt:频谱倾斜。默认开启(On)。它会对输入频谱应用一个 3 dB/oct 的倾斜,使高频比低频更容易触发。这模拟了人耳的听感(粉噪特性),让处理结果听起来更自然,尤其是在处理全频段混音时。
- Attack & Release:启动与释放。控制动态变化的速度。
- 自动模式:中心位置(50%),代表自动模式,此时 Attack 和 Release 由插件根据输入音频的特性、当前处理的频率范围以及频谱密度设置,自动计算出最合适的 Attack 和 Release 曲线。
- 手动调整:向左(低数值)调快,向右(高数值)调慢。
- Attack:启动时间。控制插件识别并开始处理问题频率的速度。
- 逆时针旋转为更快(Fast):能瞬间捕捉到突然出现的刺耳频率(如瞬态噪声)。
- 顺时针旋转为更慢(Slow):会让处理延迟一点时间,通常用于避免处理掉声音的起振感(Attack),或者让某些瞬态通过。
- 由于 Spectral Dynamics 依赖线性相位处理,过快的 Attack(尤其是极快的设置)可能会引入预振铃(Pre-ringing)或相位伪影。除非你非常确定需要处理极短的瞬态,否则建议保持 Auto 或稍微偏慢的设置。
- Release:释放时间。控制插件在问题频率消失后,停止处理的速度。
- 逆时针旋转为更快(Fast):一旦问题频率消失,EQ 修正立即消失,适合处理断断续续的干扰音。
- 顺时针旋转为更慢(Slow):处理效果会持续一小段时间,适合处理频率缓慢变化的共振或混响尾音。
- Processing Resolution:处理分辨率。Spectral Dynamics 依赖线性相位(Linear Phase)处理。线性相位处理的精度(低、中、高),分辨率越高,低频处理越精确,但引入的延迟(Latency)也越大。
手动调整 Attack、Release:针对人声的具体应用场景,虽然文档指出 Auto 模式通常是最好的,但在以下人声场景中,你可能需要手动微调 Attack 和 Release。
- 场景一:保留人声的“颗粒感”或“气口”
- 问题:你在处理人声的高频刺耳感(Harshness),但发现处理后人声变得太“平”了,失去了原本的质感和呼吸感。
- 调整:增加 Attack 时间(调慢),让处理延迟几毫秒开始。这样,人声起音瞬间的细微泛音(Transients)可以不受影响地通过,只有持续的刺耳共鸣被削减。
- 效果:既消除了刺耳感,又保留了人声的鲜活度。
- 场景二:处理持续的鼻音或共振
- 问题:人声在某个音节上有低中频的鼻音共振(Nasality),并且这个共振在音节结束后还持续了一小会儿。
- 调整:增加 Release 时间(调慢),让 EQ 的削减效果在人声结束后慢慢恢复。这可以确保整个共振尾音都被平滑地消除,而不会在声音结束的瞬间产生突兀的“抽吸”感(Pumping)。
- 场景三:处理突发的喷麦或爆音
- 问题:录音中偶尔有突然的低频喷麦声(Plosives)或衣服摩擦声。
- 调整:减小 Attack 时间(调快),确保能瞬间捕捉到这个突发的低频能量团。将 Release 设置得稍快,这样处理只在爆音发生的瞬间生效,爆音一结束立即恢复正常,不会影响后续的人声。
频谱动态(Spectral Dynamics)应用场景:
- 消除“刺耳感”与“齿音”(Harshness & Sibilance):
- 场景:人声在某些单词或音节(如“S”、“T”音)时,会在高频段(通常 4kHz - 8kHz 或更高)突然出现刺耳的声音,但整体电平并没有显著变大。
- 优势:传统动态 EQ 可能因为电平没达到阈值而不工作,或者为了处理齿音把整个高频都压下去。Spectral Dynamics 只要检测到那个特定的“刺耳”频率出现,就会瞬间将其削减,而不会影响该音节的其他部分。
- 处理“鼻音”或“共鸣峰”问题(Nasality/Resonances):
- 场景:人声在某些段落会有特定的低中频共鸣(例如 200Hz - 500Hz 的鼻音),这些频率并不是一直存在,而是随着歌词变化偶尔出现。
- 优势:你可以精准地针对那个偶尔出现的共振峰进行削减,而不需要像静态 EQ 那样一直把这段频率切掉,从而保留人声的厚度和温暖感。
- 去除录音环境中的“干扰音”:
- 场景:人声录音背景中有偶尔出现的特定频率噪音(如空调的特定啸叫、键盘敲击声的高频反射等)。
- 优势:它能像“频率吸尘器”一样,只吸走那些特定的干扰频率,而完全不影响人声主体。
区别
动态 EQ(Dynamic EQ)和频谱动态(Spectral Dynamics)区别:
- 动态均衡(Dynamic EQ):当触发信号超过阈值时,它会对选定的整个频段带宽,进行统一的增益提升或削减。
- 例如:3.5kHz,动态EQ,衰减 6 dB,当信号超过阈值时,会把这个整个频段的音量拉低。无论该频段内是 3.5kHz 还是 3.4kHz,只要触发了,它们都会一起被处理。
- 特点:处理的是宽频带。声音变化相对“整体”和“音乐化”。计算量较小,延迟极低。
- 频率追踪:无(固定频率处理)。
- 对音色影响:较明显,会改变该频段整体听感。
- 适用问题:整体浑浊、低频轰头、宽带齿音。
- 频谱动态(Spectral Dynamics):当触发信号超过阈值时,它只处理该频段内具体超过阈值的那个频率点(及其极窄的邻域),而保留该频段内其他未超阈值的频率不变。
- 例如:3.5kHz,频谱动态,衰减 6 dB,而只有 3.5kHz 处有一个刺耳的啸叫超过了阈值,Spectral 模式只会把 3.5kHz 切掉,而 3.4kHz 和 3.6kHz 的声音完全不受影响。
- 特点:处理的是极窄的频率点(即使你画的频段很宽)。极度精准,几乎不改变原始音色质感。计算量大,延迟较高。
- 频率追踪:有(可追踪移动的共振峰)。如果共振峰频率在移动(例如人声转音时的刺耳声),它能跟着移动并处理。
- 对音色影响:极小,几乎“隐形”,只去除问题点。
- 适用问题:尖锐共振、游走的啸叫、特定泛音刺耳。
选用【普通动态均衡】的情况:当你需要处理宽带的、整体的频率能量问题时。
- 去浑浊:
- 问题:男声在 300Hz-500Hz 整体听起来像闷在盒子里。
- 选择:普通动态。因为你需要降低整个中低频区域的能量,而不仅仅是某个点。
- 低频控制:
- 问题:贝斯或底鼓在 100Hz 以下太轰头,掩盖了其他乐器。
- 选择:普通动态。你需要在大动态时整体压低低频区。
- 宽带齿音:
- 问题:人声的"s"和"sh"音在整个 5kHz-8kHz 区域都太刺耳。
- 选择:普通动态。设置一个宽频段(Q=1.0),压缩整个高频区。
- 频率避让:
- 问题:人声出来时,背景音乐的整体高频需要让路。
- 选择:普通动态+外部侧链。
选用【频谱动态(Spectral)】的情况:当你需要处理尖锐的、窄带的、位置不固定的共振或噪音时。
- 游走的共振峰:
- 问题:歌手在唱高音时,某个特定的泛音(例如从 2k 滑到 2.5k)变得非常刺耳,但低音时正常。
- 选择:Spectral。普通动态无法追踪频率移动,要么切不掉,要么把不该切的也切了。Spectral 能跟着频率跑,只切那个刺耳的点。
- 吉他/弦乐的尖锐谐振:
- 问题:原声吉他拨弦时,琴体产生一个极窄的“嗡嗡”共振声,只在用力拨弦时出现。
- 选择:Spectral。它可以精准移除那个共振峰,同时保留吉他温暖的木质音色(普通动态可能会把木质音色也压暗)。
- 难以定位的刺耳声:
- 问题:你知道有刺耳声,但很难确定具体是哪个频率,因为它随音高变化。
- 选择:Spectral。画一个较宽的频段覆盖可能出现的范围,开启 Spectral 模式,它会自动“抓住”并处理那个超标的频率点。
- 保留音色的极端处理:
- 问题:需要大幅削减某个问题频率,但又不想让人听出明显的 EQ 痕迹。
- 选择:Spectral。由于它只处理超标部分,即使削减量很大(-20dB),听感上依然非常自然。
【Oeksound Soothe2】与 FabFilter Pro-Q 4 的频谱动态(Spectral Dynamics)异同:
- Soothe2:是“智能自动化”:适合快速修复、未知问题、复杂共振。它是当你不想思考具体频率,只想让声音变好听时的首选。它的算法在“自动发现”方面目前仍是行业标杆。
- Pro-Q 4 Spectral:是“手动精准化”:适合已知问题、多频段处理、高精度需求。它是当你已经听出了问题,想要像外科医生一样精准切除,且不希望有任何误伤时的首选。
最佳实践组合:
- 先用 Soothe2 挂在轨道前端,进行全局的、快速的共振平滑处理(设置较低的 Depth,只做轻微修饰)。
- 再用 Pro-Q 4 进行具体的静态 EQ 塑形,并对 Soothe2 没处理干净的、或者需要特殊动态控制的特定频段,开启 Spectral 模式进行精准打击。
【首选 Soothe2】
- “救火”场景:拿到一条录音质量很差的素材,到处都是嗡嗡声、盒状声、刺耳声,你没时间一个个去找频率。
操作:挂上 Soothe2,调大 Depth,瞬间平滑。 - 复杂游走的共振:例如电吉他solo时,随着音高变化,不同频率的共振峰不断出现,手动画 EQ 根本跟不上。
操作:Soothe2 的自动追踪算法在这种连续变化的场景下表现极佳。 - 人声去齿音/去嘶声的“懒人”方案:不想折腾 De-esser 的参数,只想快速让人声变顺滑。
操作:Soothe2 的高频段处理非常自然,通常只需调节一个旋钮。 - 创意效果:Soothe2 有一些独特的饱和度和混合(Mix)控制,适合用来做特殊的音色塑形。
【首选 Pro-Q 4 Spectral Dynamics】
- 精准手术:你明确知道问题在哪里(例如:男声在 350Hz 处有一个特定的喉音共振),且不希望影响 340Hz 或 360Hz 的音色。
操作:在 350Hz 画一个窄带,开启 Spectral,只切那个点。 - 多问题并行处理:同一条轨道上,既有低频的隆隆声(100Hz),又有中频的盒状声(400Hz),还有高频的刺耳声(6kHz)。
操作:在 Pro-Q 4 里开三个 Spectral 频段,分别处理,一个插件搞定。 - 需要外部侧链触发:你想用底鼓的信号去触发贝斯轨道上的某个特定频率的动态削减。
操作:Pro-Q 4 支持外部侧链+ Spectral 模式,Soothe2 不支持外部侧链触发其共振检测。 - 混音一致性要求极高:在母带处理或高精度混音中,你不希望算法“猜”哪里有问题,你需要完全掌控每一个被削减的频率点。
操作:使用 Pro-Q 4 的手动阈值和范围控制,确保处理的可重复性和精确性。 - CPU 资源紧张:不想加载多个重型插件。
操作:直接用 Pro-Q 4 代替“EQ + Soothe2”的组合。
处理模式(Processing Mode):决定音质和工作流的关键。零延迟(Zero Latency)、自然相位(Natural Phase)和线性相位(Linear Phase)。
- Zero Latency:零延迟。模拟模拟 EQ 的幅度响应,无延迟,CPU 占用极低。适用于绝大多数常规混音任务,特别是对延迟敏感的录音监听。
- Natural Phase:自然相位。Pro-Q 4 独有的模式。完美匹配模拟 EQ 的幅度和相位响应,声音质量最佳,无明显预振铃(Pre-ring)。推荐作为默认首选模式。适用于所有频率,特别是低频和高 Q 值设置。
- 与标准数字 EQ 对比:标准数字 EQ(通常指普通插件的最小相位模式)在幅度和相位响应上往往存在偏差(红色曲线)。
- 与零延迟对比:零延迟模式(蓝色曲线)已经非常接近完美,但在极高频(18kHz 以上)有微小偏差。
- 自然相位的表现:自然相位模式(绿色曲线)在幅度和相位上都完美匹配了理论上的模拟响应。这意味着它在修正频率的同时,保留了最自然的听感,且不会像线性相位那样产生破坏瞬态的“预振铃”效应。
- Linear Phase:线性相位。只改变幅度,不改变相位。可避免相位抵消,但会引入延迟和预振铃(Pre-ring)。仅用于解决相位问题(如母带处理中的交叉淡化、立体声增强),避免用于鼓组等瞬态丰富的素材。
关于“线性相位”的注意事项。虽然线性相位听起来很完美(因为它不改变相位),但它是一把双刃剑:
- 预振铃(Pre-ring):这是线性相位最大的副作用。它会导致瞬态(如底鼓、军鼓的敲击声)在实际声音到达前产生微弱的“回声”或“模糊感”,使声音失去棱角。
- 延迟(Latency):线性相位会引入延迟,且分辨率越高,延迟越长。文档提供了不同分辨率的延迟参考。
Pro-DS
Fabfilter Pro-DS:专业的消齿音(De-Esser)插件,主要用于消除人声录音中的高频嘶声(如“s”“sh”等齿音),同时也可用于其他高频动态控制。
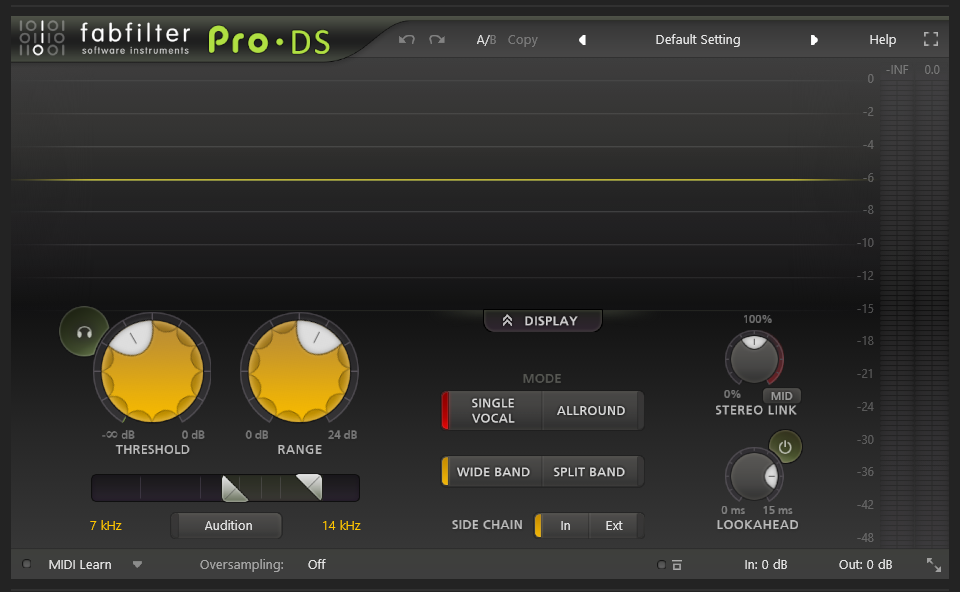
Single Vocal:仅人声模式。采用智能算法,自动识别区分人声中的齿音(如“s”、“sh”、“c”)与非齿音部分。由 Side-chain Filtering 条件触发,选出匹配的齿音部分。
Wide Band宽频模式:- 衰减齿音:对匹配的齿音部分,使用全频段动态压缩,降低齿音部分的整体音量,并且保持自然听感。即使将阈值(Threshold)设为
-INF dB,仍能保持动态范围,对齿音按 Range 衰减。 - 适用场景:人声录音后期处理(如流行、广播等需要透明化去齿音的场景)。复杂人声素材(如和声、多轨叠录),避免误伤非齿音细节。
- 衰减齿音:对匹配的齿音部分,使用全频段动态压缩,降低齿音部分的整体音量,并且保持自然听感。即使将阈值(Threshold)设为
Split Band分频模式:- 衰减齿音:对匹配的齿音部分的高频部分,进行衰减。
- 适用场景:适用于齿音特别突出且超出整体音量较多的场景。例如人声录音中,某些高频嘶声异常尖锐的情况。
Allround:全能模式。效果器监测输入信号的整体响度,对超过阈值(Threshold)的音频信号,再符合高低通滤波器(HP/LP滑块)选中的高频部分。
Split Band分频模式:- 衰减高频:对符合条件的高频部分,使用动态压缩或限制技术,按 Range 衰减,实现对高频尖锐声音的精准控制。
- 适用场景:混音总线中,对高频限制(如提升整体清晰度)。不仅适用于人声齿音处理,还可用于乐器(如镲片、吉他、弦乐高频毛刺)或母带阶段的高频优化。
Wide Band宽频模式:- 衰减信号:对符合条件的整个频段,使用全频段动态压缩或限制技术,按 Range 衰减。
- 适用场景:适用于需要平滑处理宽频段高频噪声的场景(如人声齿音与乐器泛音混合的素材)。在母带阶段,对混音整体高频进行透明压缩,避免局部频段过度处理导致的音色失衡。
使用 Fabfilter Pro-DS 衰减齿音时,核心参数
- 频率范围:优先衰减 6800Hz(针对摩擦音),可扩展至 6000-8000Hz(核心区),但需注意高频延伸可能达 10kHz 以上。
- 阈值设置:初始设置为-30dB 至-20dB,具体需根据齿音强度调整:
- 轻齿音:-30dB 至-25dB。
- 中齿音:-25dB 至-20dB。
- 重齿音:-20dB 至-15dB。
- 衰减范围:通常 3-6dB。衰减 4dB(温和处理),严重齿音可衰减 10dB。