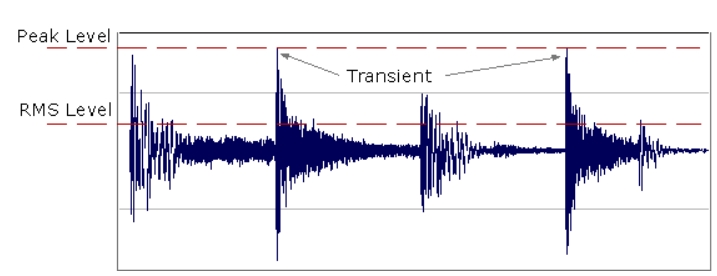
Transient(瞬态)
瞬态(Transient):声音信号中突然出现、持续时间极短的脉冲或能量爆发。瞬态是声音开头瞬间爆发的能量,决定声音的清晰度、冲击力、辨识度。
- 时间极短:持续时间通常在几毫秒到几十毫秒之间(如鼓槌敲击鼓皮、人声爆破音“P”、“B”的起始部分)。
- 能量集中:高频成分丰富,频谱上表现为陡峭的上升沿(如“S”、“T”等辅音的摩擦声)。
- 动态变化剧烈:瞬态信号的振幅变化率(dB/ms)远高于持续音(长音或元音)。
| 类型 | 示例 | 瞬态特征 |
|---|---|---|
| 打击乐 | 军鼓、镲片 | 尖锐的起音,快速衰减 |
| 人声辅音 | “P”、“B”、“T”、“K”等爆破音 | 气流冲击产生的短促脉冲 |
| 电子音效 | 合成器Lead音头的Attack | 人工设计的瞬态增强(如Glitch效果) |
人声中的瞬态
在汉语中,瞬态主要表现为发音起始阶段的突发性声学特征。发音时气流冲破阻碍、瞬间爆发成音的声音。在波形图上,它呈现为陡然突起的尖锋状细窄线条(冲直条)。
- 纯粹的瞬态:只有塞音(b、p、d、t、g、k)属于典型的瞬态。因为它们经历了“完全闭塞后瞬间爆发”的过程。
- 瞬态+紊音的结合体:塞擦音(z、c、zh、ch、j、q)在发声时是“先破裂,后摩擦”,因此在语图上表现为瞬态与紊音紧密结合成一个不可分割的单一音素。
- 非瞬态:绝大多数声母不是“瞬态”,由于发音时气流并未经历“完全闭塞后突然放开”的过程,因此不属于瞬态。例如:擦音(如 f、s、sh)、鼻音(m、n)、边音(l)。
其他语言
在欧美语言中,强瞬态的发音,主要是指硬辅音,是语言学中辅音的一种分类,主要存在于美国英语、意大利语、西班牙语、法语和俄语等语言中。其特点是发音时舌后部向软腭抬高并爆破,即软腭化。
- 英语:硬辅音通常指清辅音,如[p]、[t]、[k]等,而与之相对的浊辅音(如[b]、[d]、[g])则被称为软辅音。
- 俄语:硬辅音包括非腭化辅音,如[п]、[б]、[м]、[т]、[д]等,而腭化音则属于软辅音。例如,[brat](兄弟)中的[s]是硬辅音,而[bra](拿)中的[s]是软辅音。
- 其他语言:在意大利语、西班牙语和法语中,字母c、g在元音a、o、u前发硬辅音,即[k]或[g]音。
瞬态功能
- 清晰度塑造:瞬态缺失会导致辅音模糊(如“T”音不清),影响语音辨识度。
- 节奏强化:歌词中辅音的瞬态峰值能增强音乐律动感,尤其在说唱或流行人声处理中。
- 注意事项:录音时需保留瞬态细节,避免过度压缩;混音中可通过瞬态增强插件突出辅音冲击力。
人声中的强瞬态
人声的强瞬态具有极强的规律性,它们几乎总是出现在声音的“起音”(Attack)阶段:
- 字头(发音起始处):这是瞬态最密集的位置。每一个带有爆破或摩擦性质的汉字或单词,其最开头的几毫秒到几十毫秒,就是瞬态发生的地方。比如“澎湃(péng pài)”,“p”的发音起点就是瞬态峰值。
- 句首与重音词:一句话的第一个字,或者句子中被刻意强调的重音词汇的开头,往往带有全句最强的瞬态。这是人类语言为了传递语气和节奏感而自然形成的特征。
不形成强瞬态:
- 气声与耳语:说话时故意带有的大量气息感(如温柔的耳语),由于缺乏声带的紧密闭合和强力撞击,整体波形非常柔和,几乎不存在尖锐的瞬态。
- 字与字之间的连读过渡:在流畅的说话中,为了保持语意连贯,某些字与字之间的衔接会非常平滑,这种过渡段也不具备强瞬态。
语气决定强瞬态
语气(或者说情感强度)直接决定了人声瞬态的“硬度”和“爆发力”。在语音合成与播音主持领域,这种由语气和情绪带来的瞬态变化,通常可以从以下几个维度来总结:
高亢激昂型(强瞬态爆发):
- 当人声带有极度兴奋、愤怒、坚定或高亢的情绪时,声带的闭合会非常紧密,气息冲击力极强。
- 形成表现:在感叹句、排比句或重读词(如“崛起”、“爆发”、“必须”)上,会形成陡峭的基频下降趋势和极强的能量峰值。
- 瞬态特征:字头(辅音)的爆破感极强,甚至带有“顿挫有力”的冲击力。在声学上,这表现为共振峰分布高度集中,辅音爆发更强,整体频谱亮度大幅提升。
- 典型场景:热血动漫台词、激昂的颁奖致辞、演讲中的情绪爆发点。
紧张急促型(高频密集瞬态):
- 在紧张、恐惧或急切的情绪下,语速会显著加快,气息短促。
- 形成表现:字音变得短促,语句中的停顿极少且短暂,语言密度极大。
- 瞬态特征:由于语速快且字字紧逼,瞬态之间的间隔被极度压缩,形成一连串密集、尖锐的瞬态冲击。这种高密度的瞬态会让声音听起来非常有攻击性和紧迫感。
- 典型场景:紧急播报、争吵中的急促辩解、悬疑剧情中的紧张对白。
疑重强调型(重瞬态顿挫):
- 当表达严肃、庄重、深沉或带有强烈质疑的语气时,声音会显得分量极重。
- 形成表现:发音时音强而着力,色彩浓重,语流中的顿挫多且时间长。
- 瞬态特征:每一个重音字的起音(Attack)都会被刻意加强,形成非常明显的重瞬态。这种瞬态不像激昂型那样“炸裂”,而是显得更加厚重、沉稳,带有强烈的“颗粒感”和决断力。
- 典型场景:纪录片旁白、严肃的法庭陈述、表达强烈不满或深思时的重音。
轻柔舒缓型(弱瞬态平滑):
- 在温柔、悲伤、低沉或耳语的状态下,声带闭合不全,气息流出缓慢。
- 形成表现:声音偏暗偏沉或轻松明朗但不着力,语势轻柔舒展,语速徐缓。
- 瞬态特征:字头的爆破音和摩擦音被大幅弱化,瞬态的峰值变得非常圆润、平缓,甚至几乎消失。声音的起音阶段(Attack)呈现出缓慢的振幅爬升,听感上极其平滑,没有任何刺耳的棱角。
- 典型场景:深夜电台、温柔的睡前故事、悲伤的独白或秘密的耳语。