Leapwing Audio 插件
Leapwing Audio是一家专注于数字音频处理插件开发的厂商,其产品以算法创新和操作便捷著称,核心团队由格莱美奖获得者组成,产品覆盖母带处理、混音优化等领域。
- Leapwing Audio
Al Schmitt:智能一键式混音插件,由传奇制作人兼工程师 Al Schmitt 签名插件拥有 6 个独特的配置文件:人声、钢琴、贝斯、铜管、弦乐和混音(总线)。 - Leapwing Audio
Joe Chiccareli:专为音乐制作人设计的工具,旨在复刻获奖工程师和制作人 Joe Chiccarelli 标志性音效。包含均衡、压缩、失真等效果器,快速实现专业级声音处理效果。
- Leapwing Audio
Centerone:专为音频专业人士设计的插件,主要用于在不改变全景或频谱特性的情况下调整幻象中心信号。 - Leapwing Audio
Stageone:多频段声场增强插件,主要用于调节立体声的宽度与深度,改善立体声混音的声音场景,同时支持单声道信号的立体化处理。
- Leapwing Audio
Rootone:低频激励器。通过次谐波生成优化低频表现。为您的低频带来冲击! - Leapwing Audio
UltraVox:人声处理器。包含 4 种高度优化的算法:压缩、门限、谐波和空气。专为任何想要快速获得美妙人声声音而设计。 - Leapwing Audio
Dynone3:多段压缩器。多段压缩器。其核心功能包括动态压缩、多频段并行处理和音调调节,可优化音频细节并保持原始动态。 - Leapwing Audio
LimitOne:限幅器。采用独特的混合算法设计,可在频域和时域提供自适应动态控制。
RootOne
Leapwing Audio Rootone:低频谐波激励器。有三段低频带,可以调节交叉部分。每个频段按着八音度的方式设置,Rootone 的内部算法,会对每个频段进行信号振幅和相位分析,在该频段上生成一个干净的、相位对齐的次谐波。然后,将每个频段的信号发送到 Harmonics (饱和器、动态和衰减模块),再次生成四次谐波作用于中低频。在 Harmonics 可提升饱和度。这有助于低频声音穿透在较小的扬声器上。
传统的次谐波发生器容易发生相位偏移,导致低频和其他信号脱节分离。而 RootOne 采用的方法很好地避免了这个问题。不仅不会对信号的音高产生偏移,还会生成与源信号相位同步的子谐波。
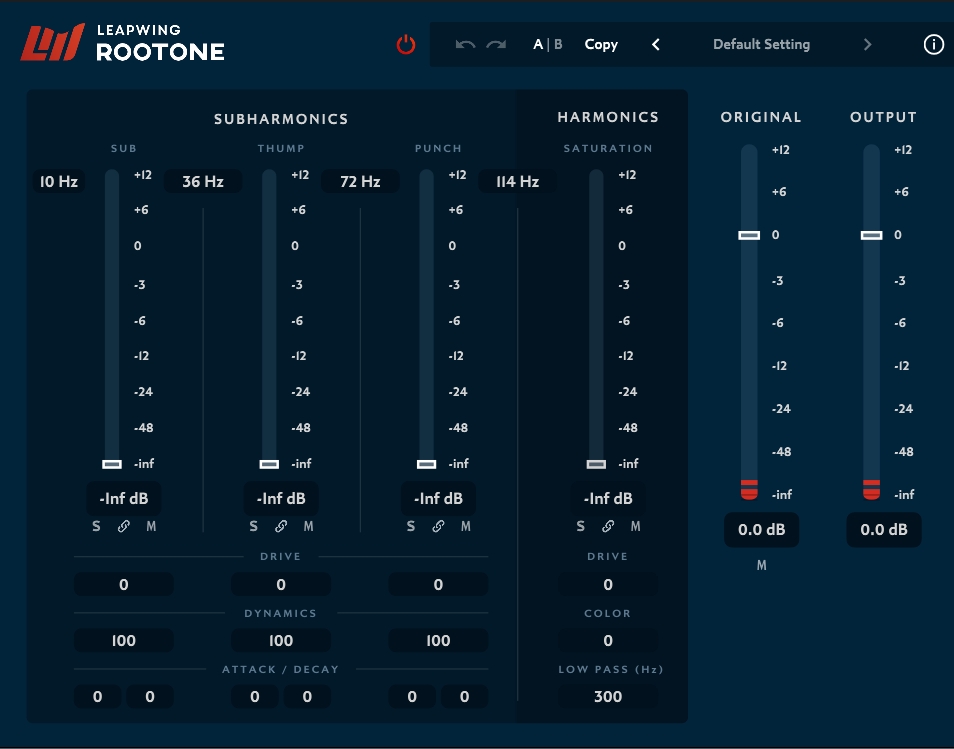
Subharmonics 区域:
- Crossover Frequencies:交叉频率,四个频带之间的交叉频率是可变的。默认值拐角频率分别为36Hz、72Hz和114Hz。点击值,将打开一个带有滑块的弹出窗口,允许您快速拖动
- Sub:最低频率。该较低拐角频率的频率范围为 8Hz ~ 30Hz,默认值为10Hz。子带上角频率可以从 32Hz ~ 56Hz 调整。
- Thump:频带范围是从 62Hz ~ 104Hz。
- Punch:频带范围是从从110Hz ~ 196Hz。
- Level Faders and Meters:电平衰减器和仪表。垂直条形图显示 RMS 水平连续柱和峰值水平。
- Solo Link Mute:每个控件可实现独奏、链接和静音。
- Drive:驱动器,调整发送电平,采用后级推子,发送到第四个“饱和”带。您设置的驱动器越高,发送的频带级别就越多到饱和段。
- Dynamics:动态功能,可控制新生成的低频的动态范围。每个频带的频率,基于原始信号。在 100%时,它会跟踪原始信封级别及其设置。如果减少,它将以更小、更高的频率产生新的频率动态范围。
- Attack & Decay:这些控制会影响子频率的整体振幅包络形状。
- Attack:允许您增强初始攻击包裹以尽量减少“燃烧”(flamming),即源可能发生的倍增效应。例如,在低频之前发生更高频率点击的踢踏鼓“boom”能量积聚。攻击设定值越高,能量越大初始升压被施加到相应的子频率。
- Decay:控制源信号瞬态后子频率持续的时间能量耗散——在短衰减设置和快速瞬态材料的情况下,亚频率会非常快地衰减,并且在瞬态结束后不会发出声音。衰减值越高,子频率的能量持续时间越长。
- Level Fader and Meter:在受所用驱动器电平影响的信号下,此电平推子调整生成的新谐波。注意,即使没有通过亚谐波驱动部分发送信号,饱和段可以根据原始输入信号产生谐波。为了增加可以创建的谐波的复杂性,从每个亚谐频带发送的信号会创建这些子频率的谐波。
例如,如果你有一个 80 Hz的输入音调,你可以从基频得到 160 Hz、240 Hz 和 320 Hz的次谐波,也可以得到 120 Hz(40 Hz的3次谐波)和200 Hz(40 Hz的5次谐波)等等!
垂直条形图,以连续柱显示 RMS 水平,以单个条形显示峰值水平,当出现任何新的最大值时,该条形会保持三秒钟。衰减器设置以dB为单位显示。 - Drive:此驱动级别控制“饱和度”部分将产生多少饱和度/失真。通过单击该值,将打开一个带有滑块的弹出窗口,您可以将设置快速拖动到所需的级别。
- Color:随着电平的增加,这种控制将失真特性从对称变为非对称。主观上讲,低设置会给你带来更像磁带的失真,而接近100的高值会听起来更像管子。
- Low Pass:此设置调整饱和部分上的最终低通滤波器。如果你不想在中频产生谐波,你可以设置一个低通滤波器频率来更快地滤除谐波。低通频率范围为 100 Hz至 1 kHz;默认值为 300Hz。
- Original Level:这控制了混合到输出中的原始或干燥信号电平的量。此控件允许您控制干/湿平衡。
- Mute Original:在不改变衰减器电平的情况下,将输入信号静音——只播放次谐波和谐波。
- Output Level:最终输出微调器,允许您根据DAW中增益分级的需要补偿增加的增益。集成电平表显示LUFS中的K加权响度,并具有3秒的峰值条。默认设置为0 dB。
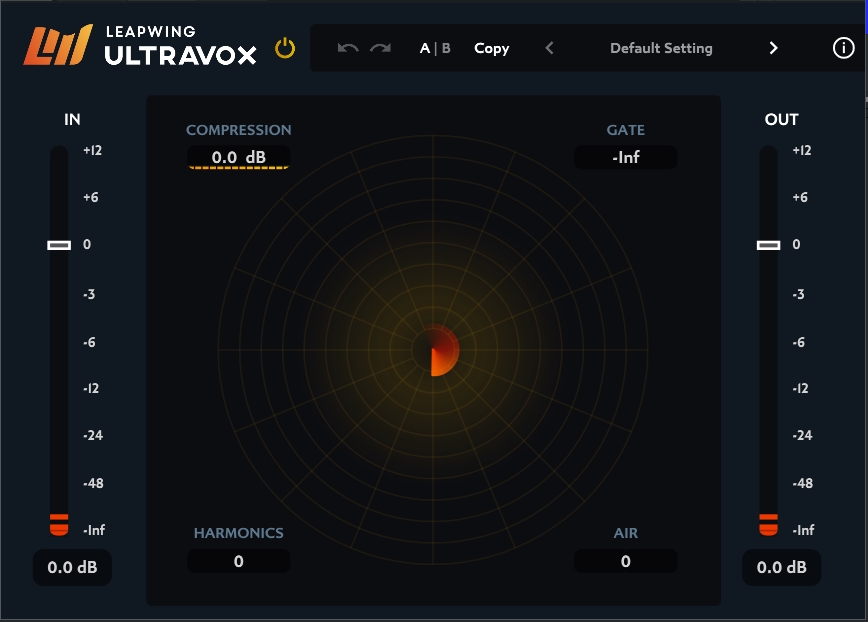
- 压缩器:旨在消除人声表演中的峰值并平衡人声,从而实现一致的水平,而不会出现不必要的伪影。
- 门限:一是减少室内噪音,二是减少因压缩而产生的呼吸声和嘴音。具有可变的依赖于程序的(中长)启动时间和(短)释放时间。
- 谐波:主要为您提供二阶和三阶谐波,使您的声音具有优美的特征。
- 空气感:集中在 12kHz 左右的均衡,使人声明亮而不会产生刺耳感。凭借其增强和剪切功能。在不引入刺耳声的情况下为人声增添清脆感。
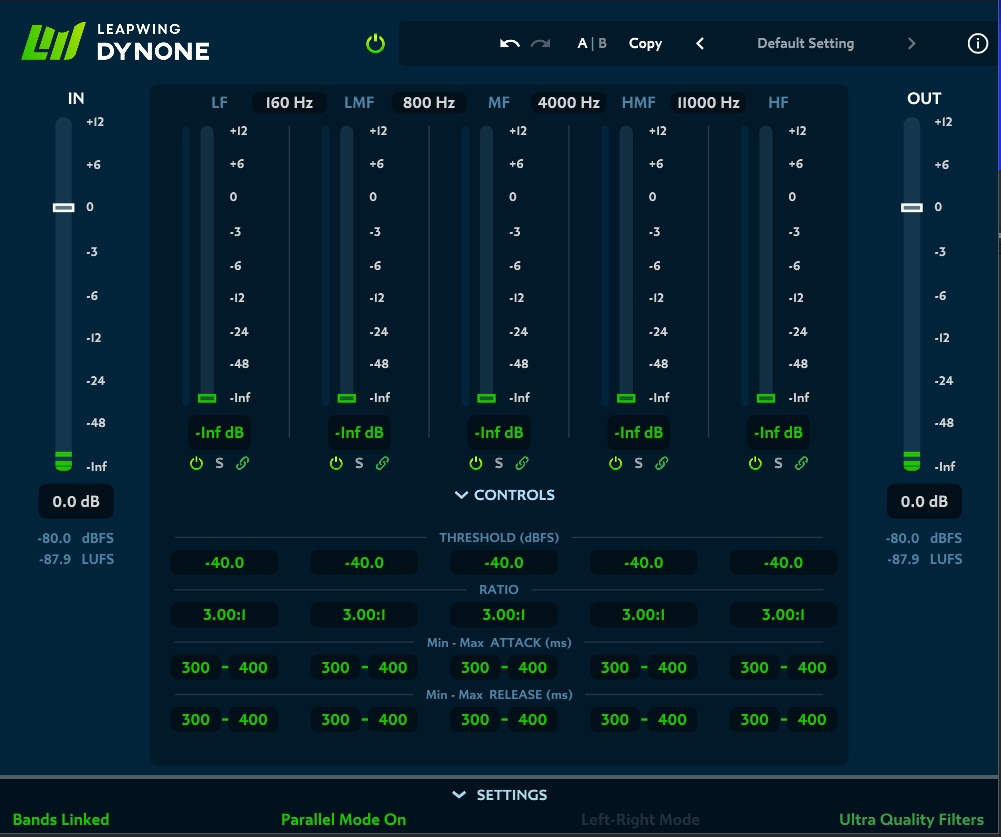
- 动态压缩:通过向下压缩(降低峰值)和/或平行压缩(提升柔和部分)平衡信号强度,支持可变开始/释放时间以减少失真感。
- 多频段处理:独立调节5个频段的电平,通过增强中低频或高频来调整音色,适用于不同音乐流派的需求。
- 音调控制:无需牺牲原始动态即可调整音调平衡,例如通过提升中频增强鼓点表现。
Harmonics 区域:
UltraVox
Leapwing Audio UltraVox:人声处理器。包含 4 种高度优化的算法:压缩、门限、谐波和空气。专为任何想要快速获得美妙声音而设计。用于录音、制作和混音。
它配备了 4 种独特的算法,每种算法都针对任何类型的人声进行了优化:
Dynone3
Leapwing Audio Dynone3:多段压缩器。其核心功能包括动态压缩、多频段并行处理和音调调节,可优化音频细节并保持原始动态。
LimitOne
Leapwing Audio LimitOne:限幅器。提供频域与时域结合的动态控制功能。其核心算法由 Pufferfish (频域处理器)和 Hedgehog (时域处理器)组成,通过优化频谱能量分布和塑造瞬态来实现自适应动态管理。由两种主要算法组成,代号为 Pufferfish 和 Hedgehog。Pufferfish 是一种频域处理器,旨在针对给定的 Drive 和 Ceiling 级别优化整个频谱中的能量分布。另一种描述方式是:全自动自适应多频带动态控制器。Hedgehog 是一种时域处理器,其主要目的是塑造瞬态。它使用共享两个相同参数(Drive 和 Ceiling 级别)的自适应控制系统。